Mirror archive
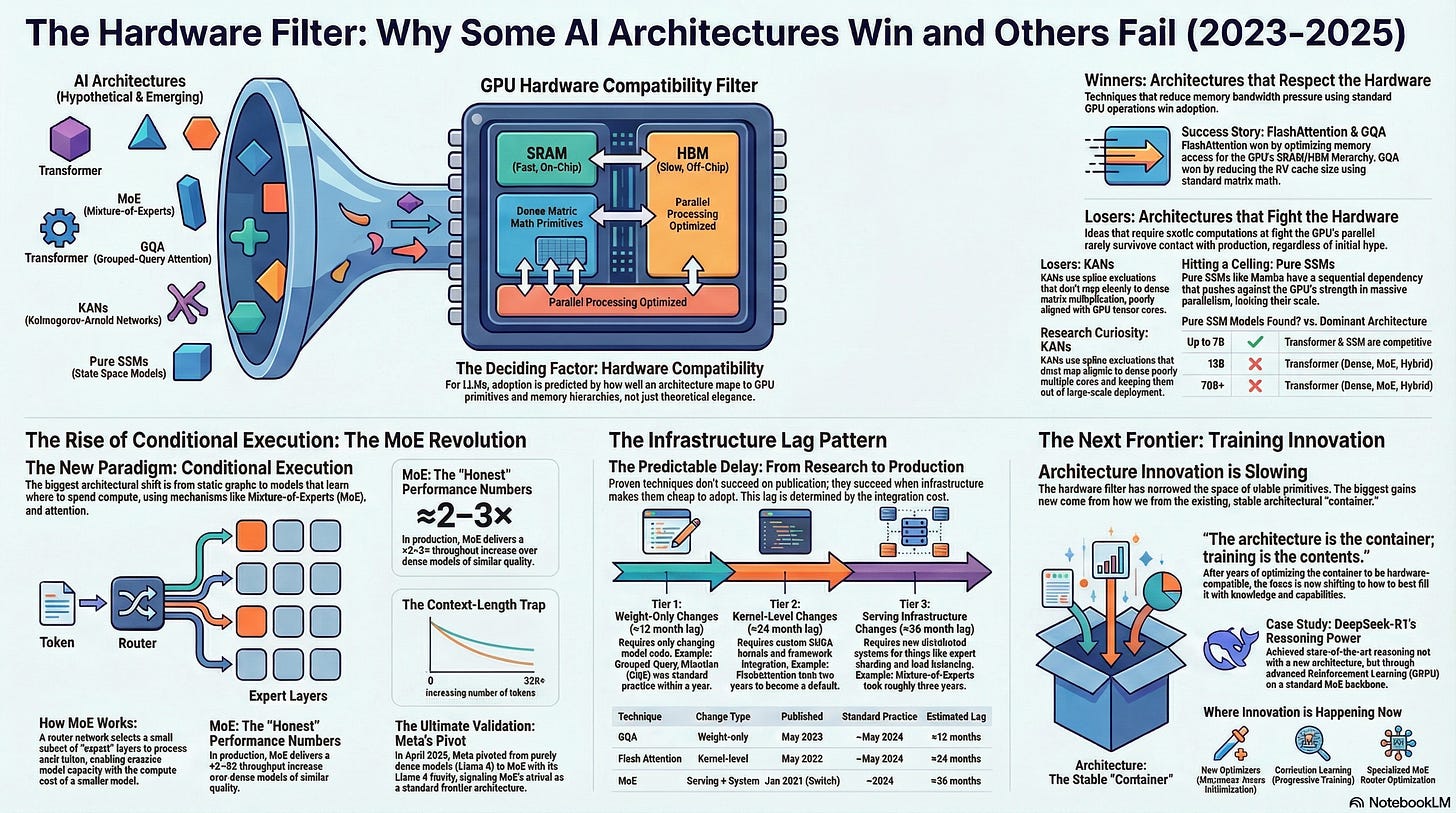
What Actually Works: The Hardware Compatibility Filter in Neural Architecture (2023–2025)
The longer quantitative essay and dataset-backed argument for why hardware compatibility predicts which architectures reach production.
TL;DR
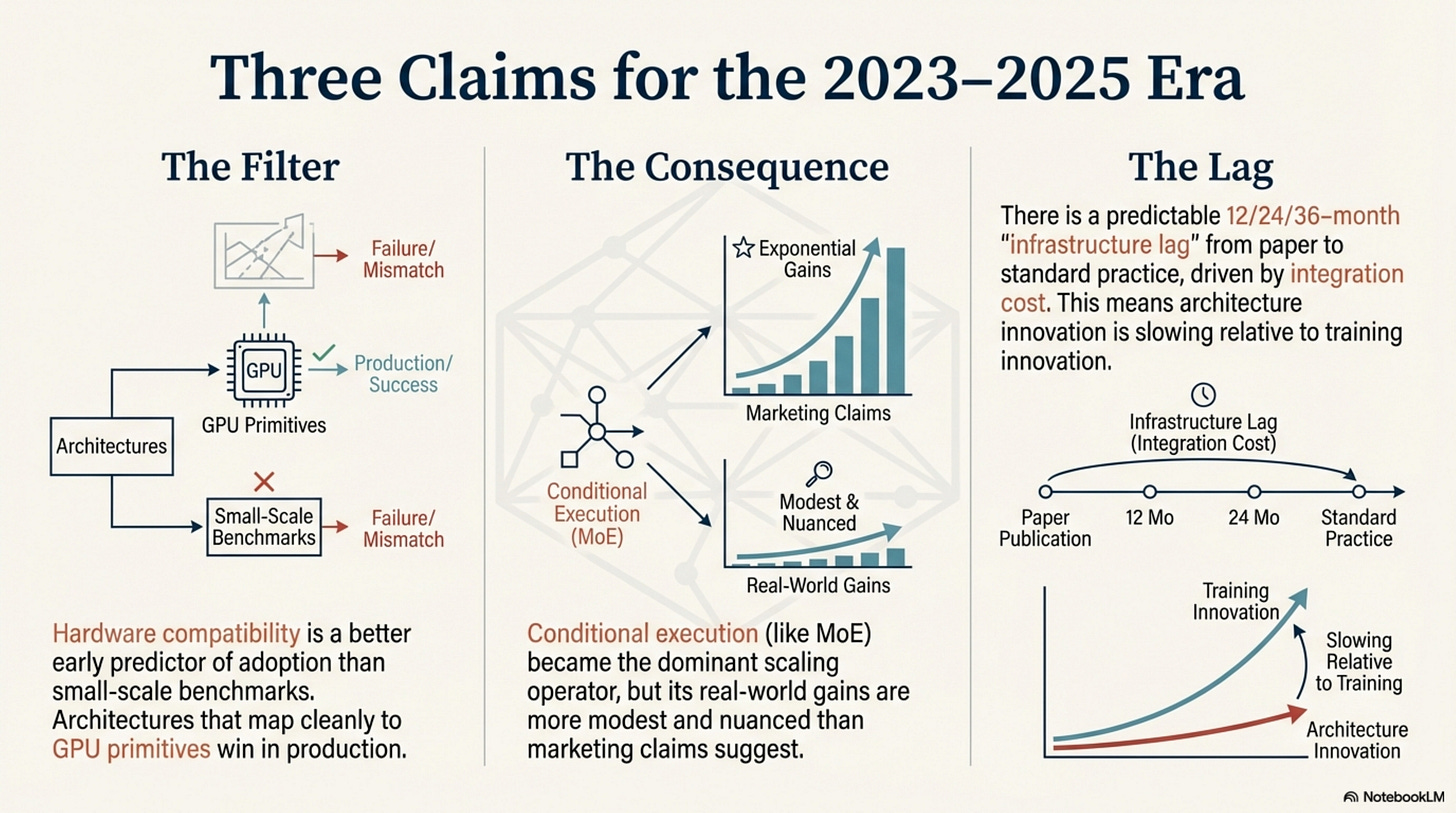
- Hardware compatibility—not just benchmarks—explains which architectures actually make it into 2023–2025 production LLMs.
- FlashAttention, GQA/MLA, and MoE win because they map cleanly onto GPU primitives and memory hierarchies; KANs and pure SSMs don’t.
- There is a predictable 12/24/36‑month “infrastructure lag” from paper to standard practice, driven by integration cost (weights → kernels → serving).
- Architecture has become a relatively stable container; the biggest gains now come from training innovation (RL-style post-training, optimization, data curation) on top of that container.
The Scroll Map
Here’s the path this article takes:
- Act I — The Compatibility Filter – Why hardware‑compatible primitives (FlashAttention, GQA/MLA, MoE) cross the infra chasm while KANs and pure SSMs stall.
- Act II — The Conditional Execution Revolution – How learned routing (attention, MoE, sparse patterns, LoRA-style adapters) became the dominant composition operator.
- Act III — The Infrastructure Lag Pattern – A 12/24/36‑month heuristic for when new primitives and systems actually reach production.
- Appendix — Evidence Tables – Model audits, MoE speedups, SSM ceiling, adoption timelines, and training‑innovation case studies.
- Glossary & Key Concepts – Short, detailed explanations of the main acronyms and primitives used throughout.
- Hardware & Kernel Primer – How GPU primitives, kernels, and frameworks create the Hardware Compatibility Filter and Infrastructure Lag Pattern.
- Bibliography & References – Grouped primary/secondary sources with one‑sentence explainers for each citation.
Introduction
In “Neural Architecture Design as a Compositional Language,” we established that architecture evolved from hand-crafted hierarchies to modular component libraries. The Transformer validated this: uniform blocks, structured composition rules, and emergent specialization through training.
We ended with three open questions. What primitives belong in the toolkit beyond attention and MLPs? What composition operators enable scaling? How do we train compositional systems effectively?
Two years of production deployments provide answers, but not through the lens most researchers expected. The organizing principle of the last 24 months isn’t expressiveness or theoretical elegance. It is hardware compatibility.
By “hardware compatibility,” we mean a concrete set of properties: operations that can be expressed as dense matrix multiplications on tensor cores, memory access patterns that respect the SRAM/HBM hierarchy, and enough regular parallelism to saturate modern GPUs. GPU architectures—optimized for these dense, parallel primitives—create a filter. Techniques that map naturally to them tend to win; techniques that fight them rarely survive contact with production, regardless of benchmark results on small models.
Hardware is not the only determinant of adoption—data availability, optimization effort, and product fit all matter—but when we compare architectures across labs in 2023–2025, hardware alignment is the strongest common constraint that shows up repeatedly in both open-weight releases and closed-model behavior.
This post examines the 2023–2025 era through three perspectives:
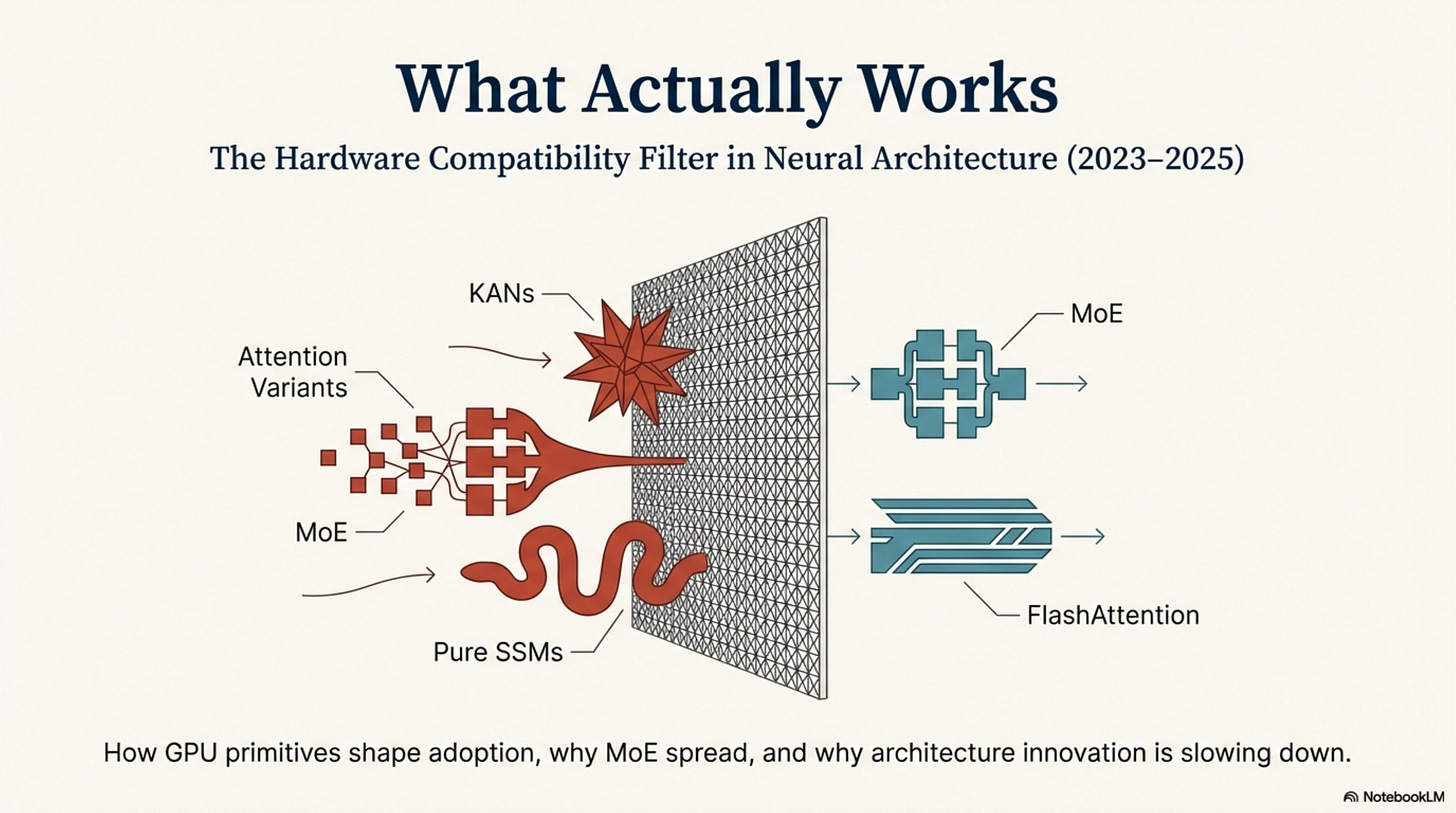
- Act I: The Compatibility Filter — How Flash Attention, MoE, and attention variants succeeded by exploiting GPU architecture, while KANs and pure SSMs failed by fighting it.
- Act II: The Conditional Execution Revolution — How learned routing (attention, MoE, sparse patterns) became the defining composition operator, replacing designed computation graphs.
- Act III: The Infrastructure Lag Pattern — Why Flash Attention took 24 months to become standard, why MoE took 36, and how to predict adoption timelines.
We argue for three claims, using production-style evidence and public model documentation:
- Hardware compatibility is a better early predictor of adoption than small-scale benchmarks.
- Architecture innovation is slowing relative to training innovation; for the foreseeable future on today’s GPU-centric stacks, the leverage is likely in optimization and data, not entirely new primitives.
- Pure SSMs have not yet scaled to frontier models; in practice, hybrids appear to be the effective ceiling today (see Appendix, Table 3).
All three are falsifiable. For example, a technique that is clearly misaligned with GPU primitives but still becomes standard at frontier scale would directly challenge the hardware compatibility thesis; a pure SSM frontier model would falsify our current ceiling claim. As of December 2025, we have not seen such counterexamples in the public record.
What doesn’t work: Speculation without production validation, marketing claims without aggregate data, and techniques that ignore deployment constraints.
What does work: Hardware-compatible primitives, permissive compositional operators, and training methods that exploit—not fight—modular structure.
Act I: The Compatibility Filter
How hardware constraints shaped what survived
Scope & Limitations
This act (and the broader analysis) focuses on large language models trained and deployed between 2023–2025 on GPU-centric infrastructure, using public papers, model cards, and system documentation as primary evidence. Closed-source models are included only to the extent that their internals can be inferred from public disclosures and third-party analyses; we do not claim completeness over proprietary experiments. All heuristics here (e.g., hardware compatibility as a filter, 12/24/36-month adoption lags) are empirical patterns observed in this window, not guarantees, and may not generalize to future hardware or domains outside production-scale LLMs. For definitions of key terms, see the Glossary and Key Concepts section; for a deeper look at how hardware and kernels interact with these ideas, see the Hardware and Kernel Primer section.
1. The Attention Bottleneck
By early 2023, the Transformer architecture faced a crisis, but it wasn’t about intelligence. It was about memory. The quadratic cost of attention (O(n2)) is often cited as a computational problem, but in practice, it is a memory movement problem.
At 128K context length, the Key-Value (KV) cache for a 70B model grows to hundreds of gigabytes, exceeding the HBM (High Bandwidth Memory) capacity of even an H100 GPU. The bottleneck wasn’t doing the math; it was moving the matrices from HBM to the compute units (SRAM) and back.
Naive solutions failed because they tried to approximate the math (sparse attention patterns, low-rank approximations) rather than solve the memory movement. They broke the one thing researchers wouldn’t compromise: the exactness of the attention mechanism. The solution that won didn’t change the math at all. It changed the memory access pattern.
2. Flash Attention: Hardware as Design Constraint
Flash Attention (Dao et al., 2022; 2023) is one of the cleanest case studies for the Hardware Compatibility Thesis. Published in May 2022, it did not propose a new neural primitive. Instead, it proposed a tiling algorithm that respects the GPU’s memory hierarchy.
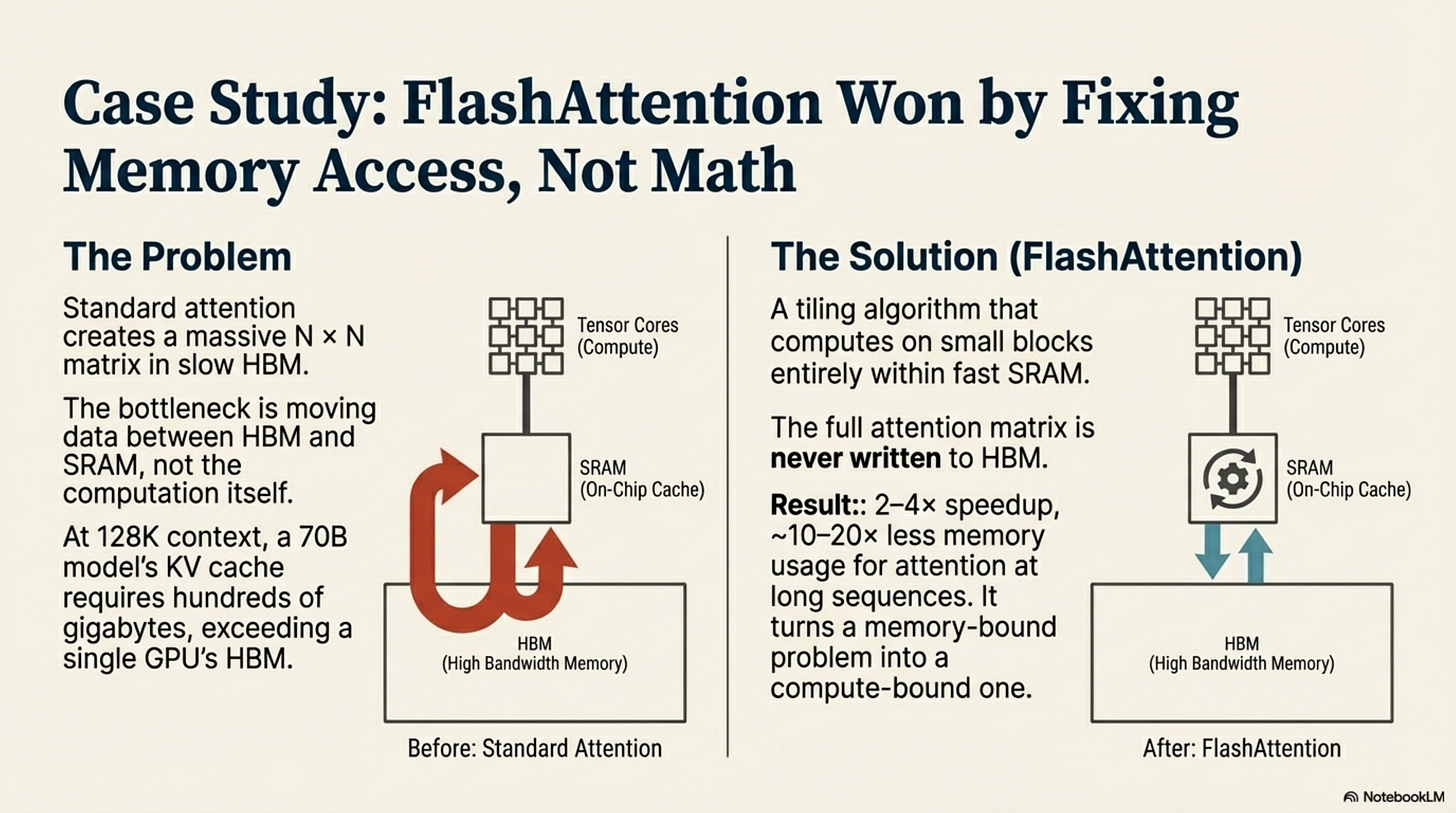
Standard attention materializes the massive N × N attention matrix in HBM, reading and writing gigabytes of data for every token generation. Flash Attention tiles the computation so that blocks of the matrix are loaded into SRAM (fast, on-chip memory), computed, and discarded without ever writing the full matrix to HBM.
The Mechanism: By keeping the computation in SRAM, Flash Attention reduces memory reads/writes by roughly an order of magnitude and delivers 2–4× speedups on attention while cutting memory usage by ~10–20× at long sequences (see Appendix, Table 4). It turns a memory-bound operation into a compute-bound one, which is exactly what GPUs are designed to handle.
The Adoption Timeline (The ≈24-Month Lag): The adoption of Flash Attention reveals a predictable infrastructure lag pattern that governs the entire field:
- May 2022: Paper published. Benchmarks show 2–4× speedup and near-linear memory scaling.
- 2022–2023 (Stage 2): Early adopters and startups integrate it manually. Custom CUDA kernels are required.
- January 2024 (Stage 3): PyTorch 2.2 officially integrates FlashAttention-2. It becomes a standard library call.
- May 2024 (Stage 4): Standard practice. Major 2024 releases (Llama 3, Gemma 2, Phi-3 and peers) rely on FlashAttention-style kernels by default (Appendix, Table 4).
It took roughly 24 months for a technique that required kernel-level changes to move from “proven research” to “standard practice.” This lag is not accidental; it is the cost of infrastructure integration. We will see this pattern repeat with MoE.
3. The Compatibility Winners
The winners of 2023–2025 all share one trait: they reduce memory bandwidth pressure without requiring new, exotic compute kernels.
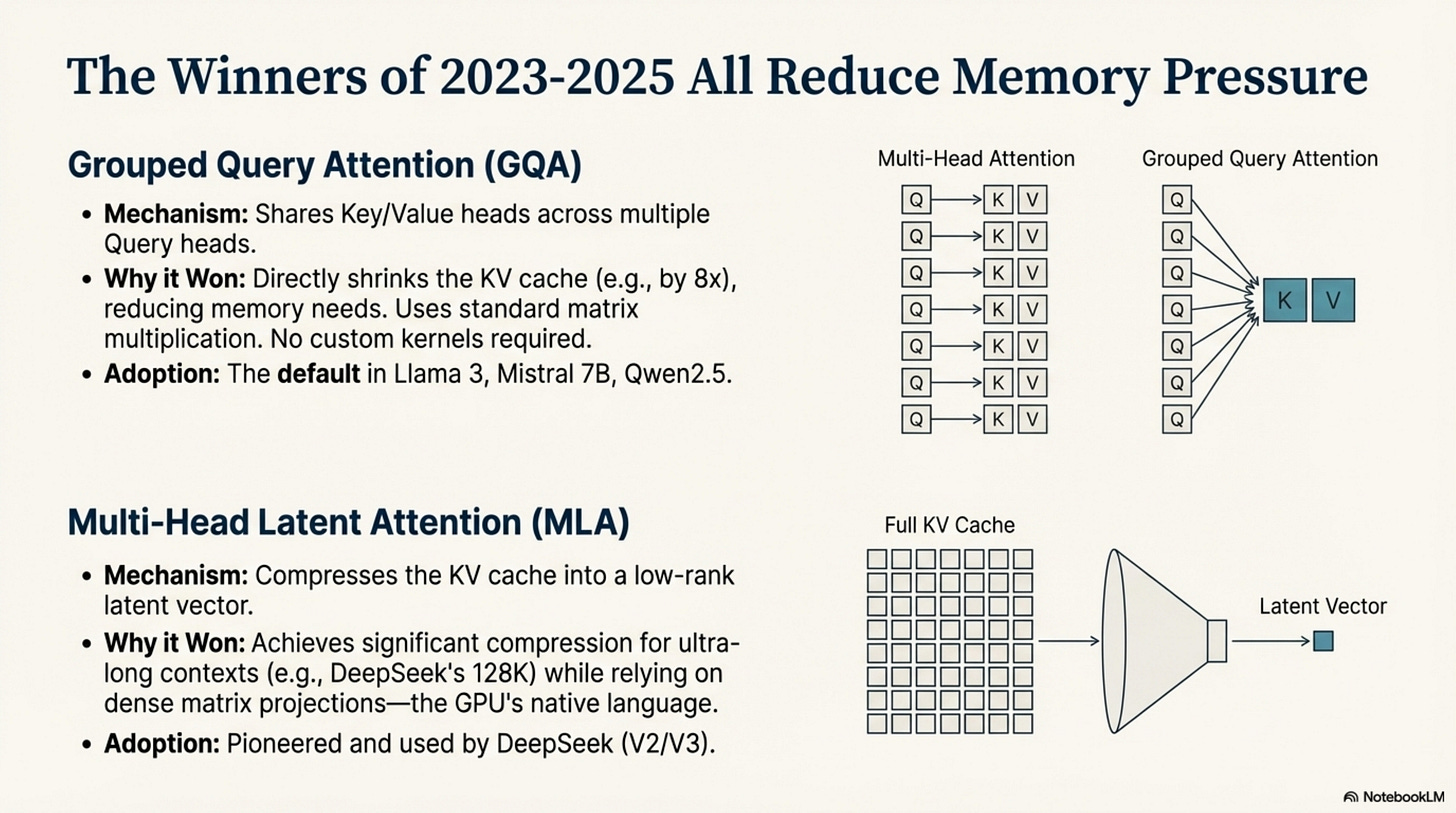
Grouped Query Attention (GQA): GQA is the dominant attention variant of 2024 in our audit, appearing in a large majority of open-weight and documented models, including Llama 3, Mistral 7B, and Qwen2.5 (see Appendix, Table 5). Its mechanism is simple: share Key and Value heads across multiple Query heads.
- Why it won: It reduces the size of the KV cache by 8× (for 8 groups), directly lowering memory bandwidth requirements. It uses standard matrix multiplication. It requires no new hardware support.
- The result: For 2024–2025 releases, it is effectively the default in most large model families we examined.
Multi-Head Latent Attention (MLA): Pioneered by DeepSeek (V2/V3), MLA takes compression further. It projects the KV cache into a low-rank latent vector.
- Why it won: It compresses the KV cache significantly (crucial for DeepSeek’s 128K context) while maintaining the expressiveness of full attention (Appendix, Table 5). Like GQA, it relies on dense matrix projections—the GPU’s native language.
MoE sits in the same compatibility bucket: when well-engineered, large MoE deployments deliver approximately 2–3× higher throughput than dense models of similar quality, not the 5–7× often claimed in marketing, and their advantage shrinks toward ≈1.3–1.5× at very long contexts as routing and KV/cache bandwidth dominate (Appendix, Table 2). The techniques that stick are those that respect the hardware, even when their real-world gains are less dramatic than the launch slides.
Contrast: The Failure of KANs Kolmogorov-Arnold Networks (KANs) generated immense hype in early 2024 by proposing learnable activation functions on edges (splines) rather than fixed weights.
- Why they struggle: Spline evaluation does not map cleanly to dense matrix multiplication. It requires disparate memory access patterns and custom kernels that are harder to implement in a way that saturates GPU tensor cores.
- The verdict (as of 2025): Despite theoretical elegance and promising small-scale results, we find no public evidence of large-scale production deployments. In practice, KANs remain a research curiosity for frontier-scale workloads, primarily because their current implementations are poorly aligned with GPU primitives.
4. SSMs: The Compatibility Boundary
State Space Models (SSMs) like Mamba (Gu et al., 2021; Gu & Dao et al., 2023) represent the most significant architectural challenge to the Transformer. They promise linear scaling (O(n)) by replacing the attention mechanism with a recurrent state update.

The Mechanism: Mamba compresses context into a fixed-size state, updating it sequentially as it processes tokens. This eliminates the KV cache entirely, theoretically solving the memory bottleneck for infinite contexts.
The Friction: Pure SSMs push against the GPU’s greatest strength: parallelism. Transformers process all tokens in a sequence simultaneously during training (parallel prefix scan). SSMs, by definition, have a sequential dependency: state t depends on state t − 1. While Mamba introduces a “parallel scan” algorithm to mitigate this, the fundamental operation is still less straightforward to parallelize than the brute-force matmuls of a Transformer.
The Evidence (The Ceiling):
- Proven Scale: Pure Mamba models exist and work at 130M, 1.4B, 2.8B, and 7B (Falcon Mamba; Appendix, Table 3).
- The Gap: We find no public evidence of a pure SSM scaling to 13B, 70B, or frontier levels (100B+); all large SSM-style deployments above 7B are hybrids (Appendix, Table 3).
- Major Lab Adoption: As of late 2025, OpenAI, Google, Meta, and Anthropic have not publicly documented pure SSMs in their frontier models. Adoption is 0/5 in our audit.
The Nuance: Hybrids exist. Jamba (AI21) and Qwen3-Next use SSM layers mixed with Attention layers.
- Why hybrids work: They route local, sequential dependencies to the SSM (efficient) and global, complex dependencies to Attention (expressive).
- The Prediction: Absent new evidence or hardware, pure SSMs look unlikely to become the dominant frontier architecture. The main bottleneck appears architectural (parallelism and in-context learning), not just a missing training trick. Hybrids are where we see real adoption today, and even they remain niche due to implementation complexity.
5. External Memory (RAG): The Compatibility Shortcut
While researchers fought over O(n2) vs O(n) architectures, the industry solved the context problem with a database. Retrieval-Augmented Generation (RAG) is the ultimate compatibility hack.
- Mechanism: Offload memory to a vector database (highly optimized for search). Retrieve only relevant chunks. Feed them to the GPU context window.
- Why it won: It requires zero changes to the neural architecture. It treats the GPU as a reasoning engine, not a storage engine.
- Adoption: Effectively universal among major commercial assistants as of 2025. ChatGPT, Claude, Gemini and similar products all expose some form of retrieval or tool-based long-context access.
Act I Synthesis: Across 2023–2025, the pattern is consistent. Flash Attention (maps to the memory hierarchy) took about 24 months to become standard (Appendix, Table 4). GQA (maps to bandwidth constraints) diffused in roughly 12 months as a weight-only change (Appendix, Tables 4 and 5). Pure SSMs (which push against parallelism) currently top out at 7B with no public frontier-scale models (Appendix, Table 3). KANs (incompatible compute paths) have no documented large-scale production deployments.
We are not designing neural networks in a vacuum. We are discovering which computations GPUs can efficiently express. Hardware acts as a ruthless filter on which ideas survive into production today.
In Act II, we will see how this filter shaped the most important composition operator of the decade: the shift from static graphs to learned, conditional execution.
Act II: The Conditional Execution Revolution
How learned routing became a first-class primitive
The defining shift of 2023–2025 was not a new layer type. It was a change in the fundamental contract of computation. In the previous era, neural networks were static graphs: every input token triggered the exact same sequence of floating-point operations. In the current era, computation is conditional—the model learns where to spend compute, not just what layers exist.
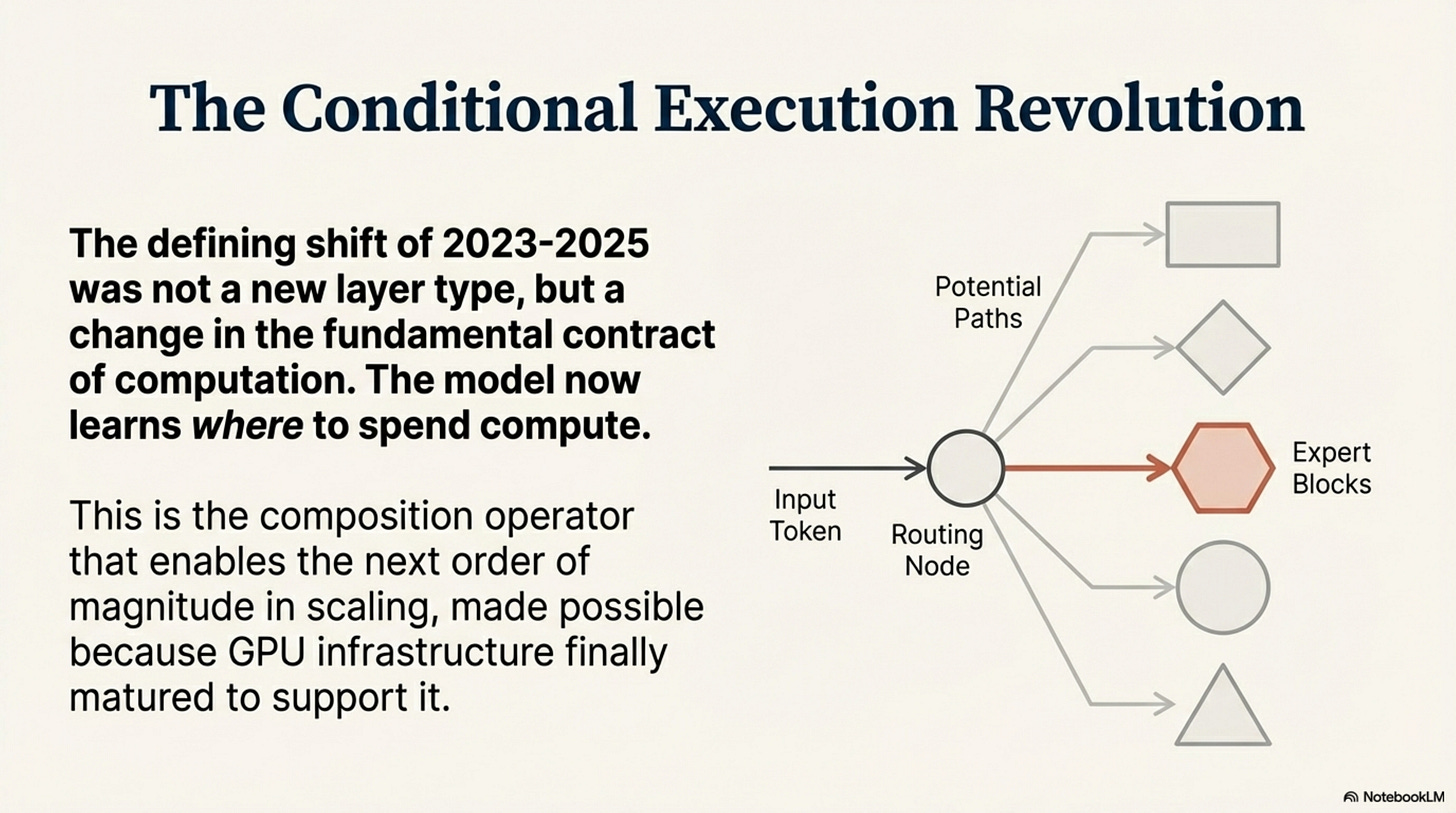
This isn’t just about Mixture-of-Experts (MoE). It is a convergence across attention, routing, and adaptation. The architecture increasingly specifies how to choose what to compute for a given token, task, or context.
1. The Conditional Execution Convergence
If we look closely at the successful techniques of the last two years, a unifying pattern emerges: they all introduce some form of learned selectivity over compute or parameters:
- MoE: “Which expert processes this token?” (hard routing of tokens to expert FFNs).
- Attention: “Which previous tokens influence this output?” (soft routing of influence over a dense attention kernel).
- Sparse Patterns: “Which positions matter?” (structured masking that skips compute for parts of the sequence).
- LoRA / adapters: “Which low-rank subspace adapts for this task?” (task-conditional parameter additions, not token-time routing).
These are not identical mechanisms, but they share a common composition operator: conditional execution. Some (like MoE and sparse attention) route tokens or positions to different compute paths at runtime; others (like LoRA) condition which parameters are active for a given task or domain.
Why did this happen now? Because GPU infrastructure finally matured to support it at scale. For years, “sparsity” was a dirty word in high-performance computing because it meant irregular memory access and thread divergence—two things GPUs hate. But with the arrival of specialized kernels and serving stacks for block-sparse operations (e.g., Triton/MegaBlocks-style MoE kernels, FasterMoE, Aurora, FlashInfer, and MoE-aware DeepSpeed/Megatron/FasterTransformer), the penalty for conditional execution dropped below the capacity and throughput gains it unlocks (Appendix, Table 2).
The thesis of Act II is simple: Conditional execution is to the 2020s what residual connections were to the 2010s—the composition operator that enables the next order of magnitude in scaling.
2. MoE: The Production Validation
For years, Mixture-of-Experts was the “technology of the future”—from Shazeer et al.’s sparsely-gated MoE (2017) through Switch Transformers (Fedus et al., 2021) and GLaM (Du et al., 2021)—always promising, but difficult to train and painful to serve. In 2024–2025, that future finally arrived. MoE is no longer an exotic research trick; it has become one of the primary strategies for scaling frontier models, especially when total parameter counts exceed what dense training and serving can economically support (Appendix, Table 1).

The Honest Numbers: Let’s strip away the marketing claims. Vendors often promise “5–7× speedups” with MoE. The reality, based on a meta-analysis of production-style deployments and system papers, is more grounded but still transformative (Appendix, Table 2):
- Realistic Inference Speedup: ≈2–3× throughput compared to dense models of similar quality at moderate context, with a median around 2.1–2.5× in our aggregated studies.
- The Mechanism: A model like DeepSeek-V3 (671B parameters) activates only 37B parameters per token. It delivers the intelligence of a massive model with the latency of a small one.
The Evidence: The list of successes is now long and growing. A few representative examples:
- DeepSeek-V3 (Dec 2024): 671B total, 37B active (DeepSeek-AI, 2024). A masterclass in load balancing and MoE + MLA design.
- DeepSeek-R1 (Jan 2025): 671B/37B MoE + MLA reasoning model with state-of-the-art math scores (DeepSeek-AI, 2025).
- Mixtral-8×7B: The model from Mistral AI (2023) that proved open-weights MoE could match or beat GPT-3.5-class systems on many benchmarks.
- Grok-1: 314B parameters, confirming MoE works at massive scale without fine-tuning, in an open checkpoint (xAI, 2023–2024).
The Narrative Climax: The Meta Pivot The clearest public signal of MoE’s arrival came in April 2025. Until then, Meta had pushed dense scaling hard—Llama 3.1’s 405B dense model was a monument to that strategy. With Llama 4, Meta introduced its first MoE family:
- Llama 4 Scout: 109B total, 17B active (16 experts).
- Llama 4 Maverick: 400B total, 17B active (128 experts).
Meta’s pivot does not mean dense models are obsolete—dense Llama variants and many closed models still exist—but it is a strong signal that at frontier scale, MoE is now considered a first-class option rather than a risky experiment (Appendix, Table 1). The Dense Era has not ended, but it now shares the stage with sparse, conditionally-executed capacity.

4. Hybrid Architectures: Principled Heterogeneity
To solve the Context-Length Trap, we are seeing the emergence of Hybrid Architectures.
Qwen3-Next is the prime example. It doesn’t use just one primitive. It uses a three-dimensional hybrid approach:
- Linear Attention for the infinite context backbone.
- Gated Attention for high-fidelity retrieval.
- MoE for feed-forward capacity.
The Principle: Route computation to the primitive that handles it best.
- SSM/Linear: Handles local, sequential dependencies (efficient).
- Attention: Handles global, arbitrary dependencies (expressive).
- MoE: Handles knowledge storage and reasoning (capacity).
While elegant, hybrids remain niche. The complexity cost of maintaining three different inference kernels usually outweighs the benefits for general-purpose models. Today, they are the solution for extreme requirements (256K+ contexts and ultra-long workflows), not yet the default for general reasoning.
5. What Didn’t Work: The Failure Mechanism
To understand why conditional execution won, we must look at what failed.
Neural ODEs (2018): Promised continuous depth and infinite adaptability.
- Why they struggled: ODE solvers are iterative and sequential. They fight the GPU’s need for massive, predictable parallelism. They won Best Paper at NeurIPS, influenced theory, and saw use in niche domains—but in our survey we find no evidence of large-scale production adoption for LLM-style workloads.
Capsule Networks: Proposed “routing-by-agreement” to solve spatial hierarchies.
- Why they struggled: The routing logic was prescriptive. It tried to enforce a specific structure (capsules) rather than creating a permissive space for the model to learn its own structure. Despite a burst of research interest, we again find no evidence that capsule-style routing became a pattern in large-scale production models.
The Lesson: Compositionality that survives is permissive, not prescriptive. MoE provides a pool of experts and a router, but it doesn’t tell the model what the experts should be. It lets gradient descent discover the structure. Capsule Networks and Neural ODEs tried to design the structure explicitly, and they did not cross the production chasm.
Act II Synthesis: Conditional execution won because it is the most general way to scale capacity without worsening the compute constraint. It maps to the GPU’s ability to handle block-sparse operations and conditional parameter usage. Llama 4’s pivot confirms MoE as a standard frontier tool, not just a research prototype.
In Act III, we will explore the final piece of the puzzle: why these transitions take so long, and where the field goes next.
Act III: The Infrastructure Lag Pattern
Why timing matters: From research to production

Flash Attention (Dao et al., 2022; 2023) was published in May 2022. It became standard practice in May 2024. Roughly two years. Switch Transformers (Fedus et al., 2021; Lepikhin et al., 2020; Du et al., 2021, for closely related MoE work) were published around 2020–2021. They reached mainstream production usage only around 2024. Roughly three years for MoE-style serving infrastructure.
Why the lag? In a field that moves at the speed of light, why does it take 24–36 months for a proven, hardware-compatible technique to reach production?
The answer is what we call the Infrastructure Lag Pattern. Techniques do not succeed when they are published. They succeed when the infrastructure makes them cheaper to adopt than to ignore.
1. The Adoption Dynamics Model
Looking across GQA, Flash Attention, and MoE, we see a recurring pattern: adoption timelines track integration cost (Appendix, Table 4). This is not a law of nature, but a useful heuristic for techniques similar to those we analyzed.

-
Level 1: Weight-Only Changes (12–18 months)
- Example: Grouped Query Attention (GQA).
- Requirement: Change the model definition code. No new kernels, no new serving infrastructure.
- Lag: Minimal. Adoption is driven by retraining cycles.
-
Level 2: Kernel-Level Changes (24–30 months)
- Example: Flash Attention.
- Requirement: Custom CUDA kernels. Integration into PyTorch/JAX.
- Lag: 24 months. This is the time it takes for a kernel to move from a research repo -> a library -> a framework stable release -> a production stack.
- Evidence: Flash Attention (May 2022) -> PyTorch 2.2 (Jan 2024) -> Standard (May 2024).
-
Level 3: Serving Infrastructure Changes (36–48 months)
- Example: Mixture-of-Experts.
- Requirement: Not just kernels, but distributed system changes. How do you shard experts across nodes? How do you handle load balancing in inference?
- Lag: 36 months.
- Evidence: Switch (Jan 2021) -> Mixtral/DeepSeek/Llama 4 (2024–2025).
Integration cost is not the only factor—vendor priorities, open-source implementations, and hype all matter—but it is the most consistent constraint we see across 2023–2025 production case studies.
The Prediction (Heuristic, Not Law): If a new technique requires kernel changes (like KANs would), do not expect broad production usage for roughly two years. If it requires serving changes, expect closer to three. If it fundamentally fights GPU primitives, treat it as research-only for current production GPU stacks.
This model would be falsified by, for example, a kernel-level change that becomes standard in under a year, or a serving-level change that diffuses in a single retraining cycle. As of late 2025, our three highlighted case studies (GQA, Flash, MoE) line up cleanly with the 12 / ~24 / ~36-month buckets in Appendix, Table 4.
2. Training Innovation: The Next Frontier
This brings us to our final and most controversial claim: Architecture innovation is slowing relative to training and optimization.
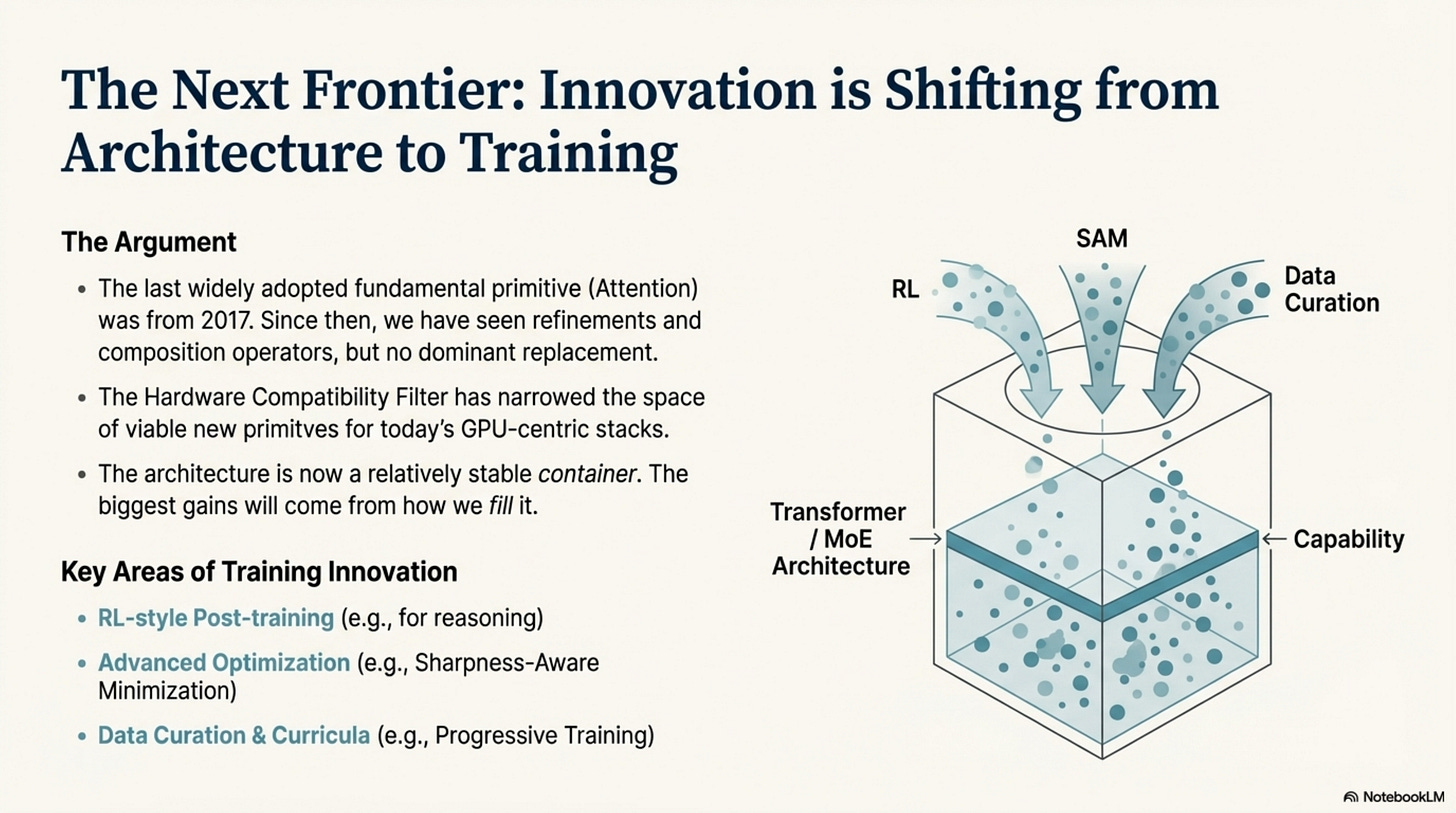
The last widely adopted fundamental primitive (Attention) was introduced in 2017. Since then, we have seen refinements (Flash, GQA, MLA), composition operators (MoE), and hybrids (attention + SSM), but no clearly dominant replacement at frontier scale. The hardware constraints have narrowed the space of acceptable operations tightly around dense matrix multiplication, making truly novel primitives harder to push through the Hardware Compatibility Filter (Appendix, Tables 2, 3, and 5).
That does not mean architectural work has stopped—SSM-style blocks, hybrids, and long-context variants are very active research areas—but the center of gravity has shifted. For the foreseeable future on today’s GPU-centric stacks, the leverage is likely to come from Training Innovation on top of this relatively stable container.
A Case Study: DeepSeek-R1 (January 2025) One of the strongest recent examples comes from DeepSeek-R1 (DeepSeek-AI, 2025). It achieved state-of-the-art reasoning performance (79.8% on AIME, 97.3% on MATH-500), rivaling OpenAI’s o1-class models.
-
The Architecture: MoE + MLA built on the same frontier-style primitives described in Acts I and II.
-
The Innovation: Reinforcement Learning at scale.
- DeepSeek-R1 was trained using Group Relative Policy Optimization (GRPO) and a carefully engineered reasoning curriculum to discover multi-step chains of thought.
- It did not introduce a new neural primitive to learn to reason. It pushed a familiar container (MoE + efficient attention) much further via training.
This is not singular “proof,” but it strongly reinforces the thesis: The architecture is the container; training is the contents. We have spent 8 years optimizing the container. It is efficient, scalable, and hardware-compatible. Now we are finally learning how to fill it.

Where Innovation Moves:
- SAM (Sharpness-Aware Minimization): Optimizing for flatter, more robust minima (Foret et al., 2020), which improves generalization and compositional behavior in many settings.
- Progressive Training: Using depth as a curriculum; several studies report ≈10–20% faster convergence versus naive deep training.
- Routing-Aware Optimization: Training the router to balance load without collapsing, improving MoE utilization and stability at scale.
Training innovations have their own lag pattern—new optimizers and RL schemes still need to be implemented, debugged, and validated—but they typically integrate faster than core architectural overhauls. We are shifting from “what to compute” to “how to train what we already compute.”
Conclusion
The story of 2023–2025 is not one of unbridled invention, but of ruthless selection.

The Hardware Compatibility Thesis explains much of the difference between techniques that survive and those that do not. Flash Attention
won because it respected the memory hierarchy. MoE won because it mapped to conditional execution. Pure SSMs have, so far, hit a ceiling around 7B because they fight parallelism (Appendix, Table 3). KANs remain research curiosities because their spline-heavy compute paths do not align with tensor core strengths.
For the senior practitioner, this offers a clear heuristic:
- Predictive: When evaluating a new paper, ask: “Does this map to GPU primitives?” If no, treat it as a research bet rather than a near-term production candidate.
- Strategic: Architecture progress is real but slower; invest a growing share of your R&D budget in training innovation (data curation, RL, optimization) instead of searching for a wholesale “next Transformer.”
- Tactical: Adopt Flash Attention and GQA wherever possible. Use MoE for scaling beyond ~10B parameters if your infrastructure budget can support it. Treat pure SSMs as research-only for frontier models until we see public evidence above 7B (Appendix, Table 3).
We are not designing neural networks in a vacuum. We are discovering which computations silicon can express efficiently. The ones that map naturally to the hardware survive at scale. The ones that don’t risk becoming historical footnotes on today’s GPU-centric stacks, regardless of their theoretical elegance.
The architecture wars are not literally “over,” but for production LLMs on 2023–2025 hardware, they have entered a slower phase. The next competitive frontier is how we train and use the architectures we already have.
Critique:
Thanks for reading Petros Rooted Layers! This post is public so feel free to share it.
Appendix: The Evidence
For the skeptical practitioner, we present the aggregated evidence underlying the claims in this post. For terminology and hardware background, see the Glossary and Key Concepts and Hardware and Kernel Primer sections.
Table 1: Major Lab Frontier Model Releases (2023–2025)
Explicit model releases by major labs, ordered roughly chronologically. Architectures are summarized from public documentation as of Dec 4, 2025.
Insight: From 2023 to late 2025, frontier lines clearly cluster into two patterns: (1) Dense / sparse transformers with ever‑better kernels (Flash Attention, GQA, long context, sparse patterns), and (2) MoE transformers (Llama 4, Mixtral) that trade implementation complexity for large capacity at similar active compute. Pure SSM models still do not appear as standalone frontier flagships; SSM/Mamba‑like blocks show up only as components inside hybrids or efficiency‑oriented models outside this list.
Table 2: The MoE Reality Check
Marketing claims vs. production-style measurements from short to long context (up to 64K–128K tokens). Summarizes Extended Dataset 1 (MoE Speedup Meta-Analysis), aggregated from Switch, Mixtral, DeepSeek-V3, deployment-inefficiency work, and Aurora-style system papers.

Insight: MoE is primarily a throughput and capacity optimizer, not a magic fix for latency or memory. It buys “more model for the same serving budget,” especially at moderate context, but still runs into bandwidth and KV-cache limits at frontier context lengths.
Table 3: Pure SSM / Mamba Evidence Gap
Where pure Mamba/SSM models have been demonstrated vs. where evidence stops (as of Dec 2025). Summarizes ssm_benchmark_findings.md.
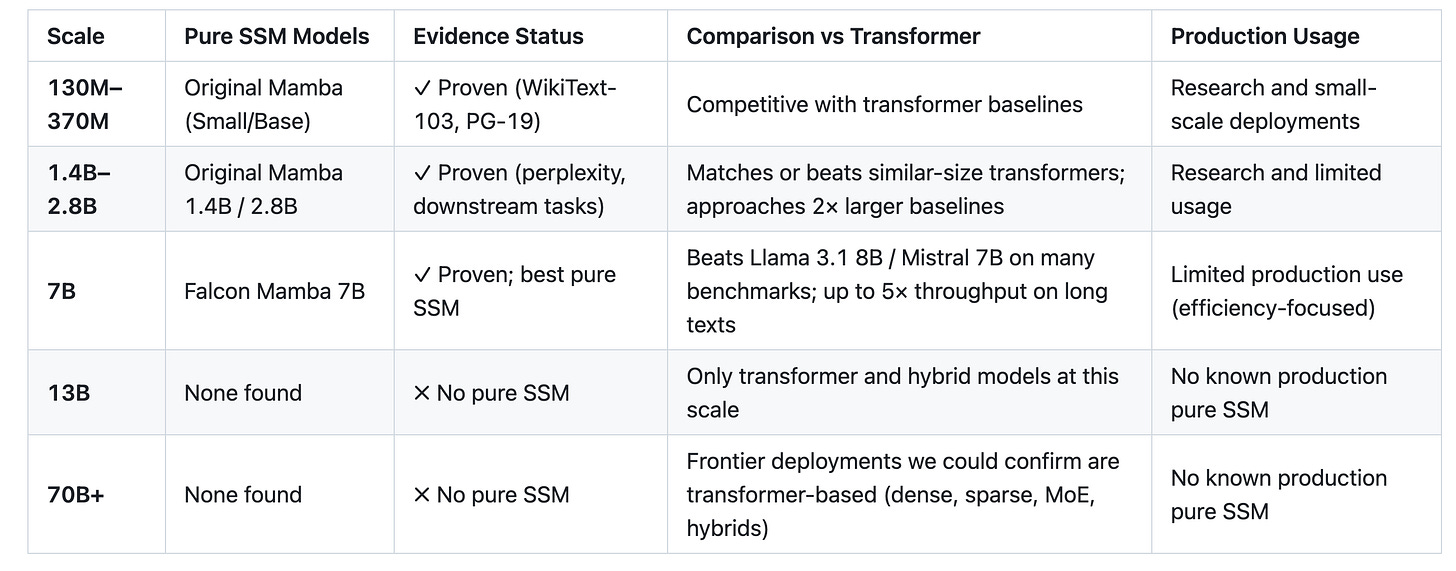
Insight: Pure SSMs are clearly viable up to 7B and can be very efficient, but in the public releases we examined there is no evidence of pure SSMs at 13B or frontier scales; above 7B, SSM-style blocks only appear inside hybrid architectures (Jamba, Falcon-H1, Qwen3-Next), not as end-to-end replacements for attention.
Table 4: Infrastructure Lag Timeline
Time from publication to standard production practice, grouped by integration complexity. Derived from flash_attention_timeline.md, MoE deployment studies, and GQA adoption data.
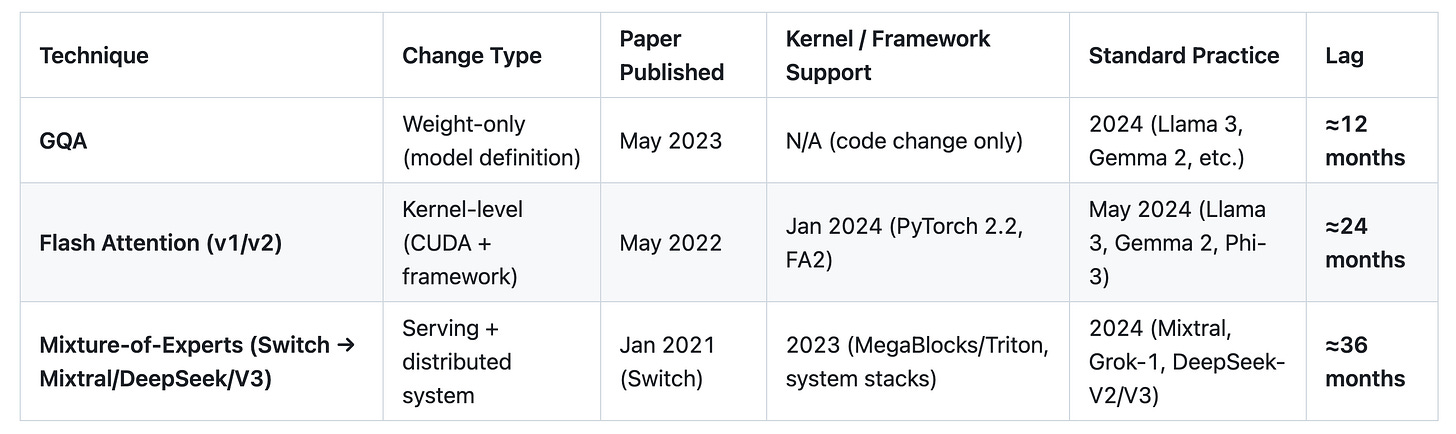
Insight: Integration cost determines adoption speed. Weight-only changes land within a retraining cycle; kernel changes take ~2 years to become ubiquitous; distributed system changes (e.g., MoE routing and large-scale sparse attention) take closer to 3 years.
Table 5: GQA / MLA / Efficient Attention Adoption
Snapshot of efficient attention mechanisms across major 2024–2025 model families, distilled from major_lab_architecture_audit.md.
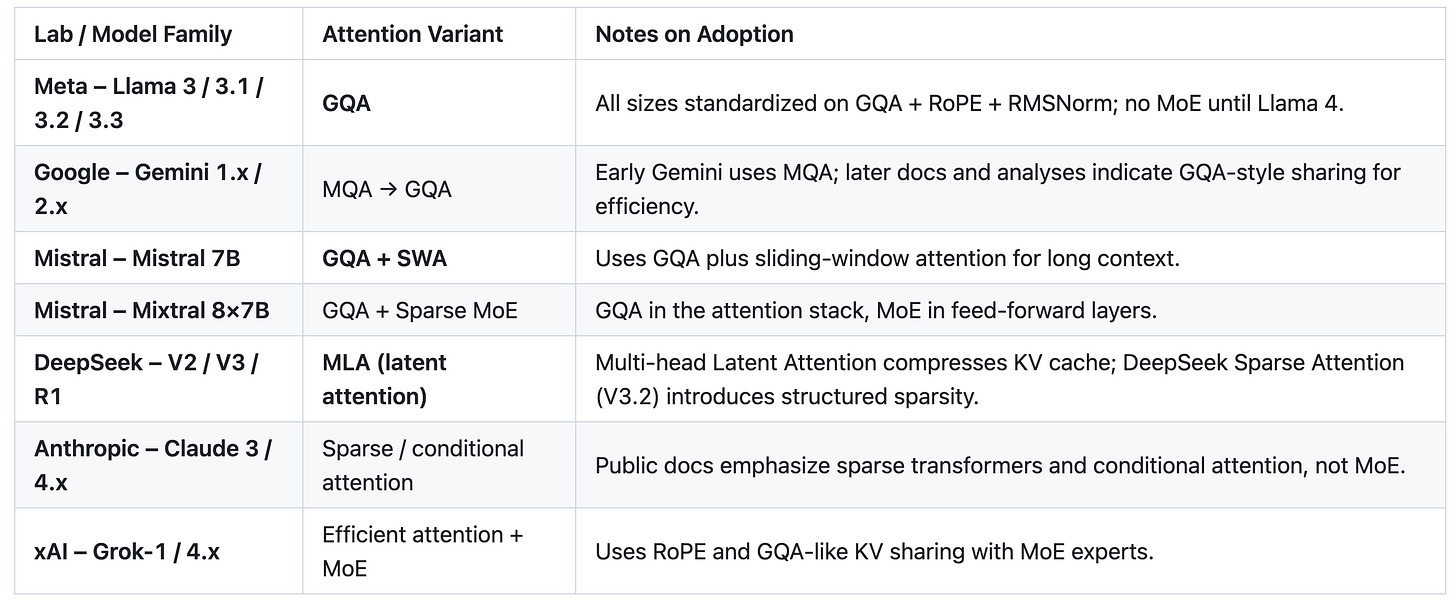
Insight: By late 2025, GQA-style efficient attention (plus MLA and sparse variants) dominates over vanilla MHA in the large models we audited. This is the weight-only, hardware-aligned optimization that diffuses fastest and forms the “background assumption” for 2024–2025 architectures.
Table 6: Training Innovation Evidence
Selected examples where training methods, rather than new primitives, drove major capability or efficiency gains.
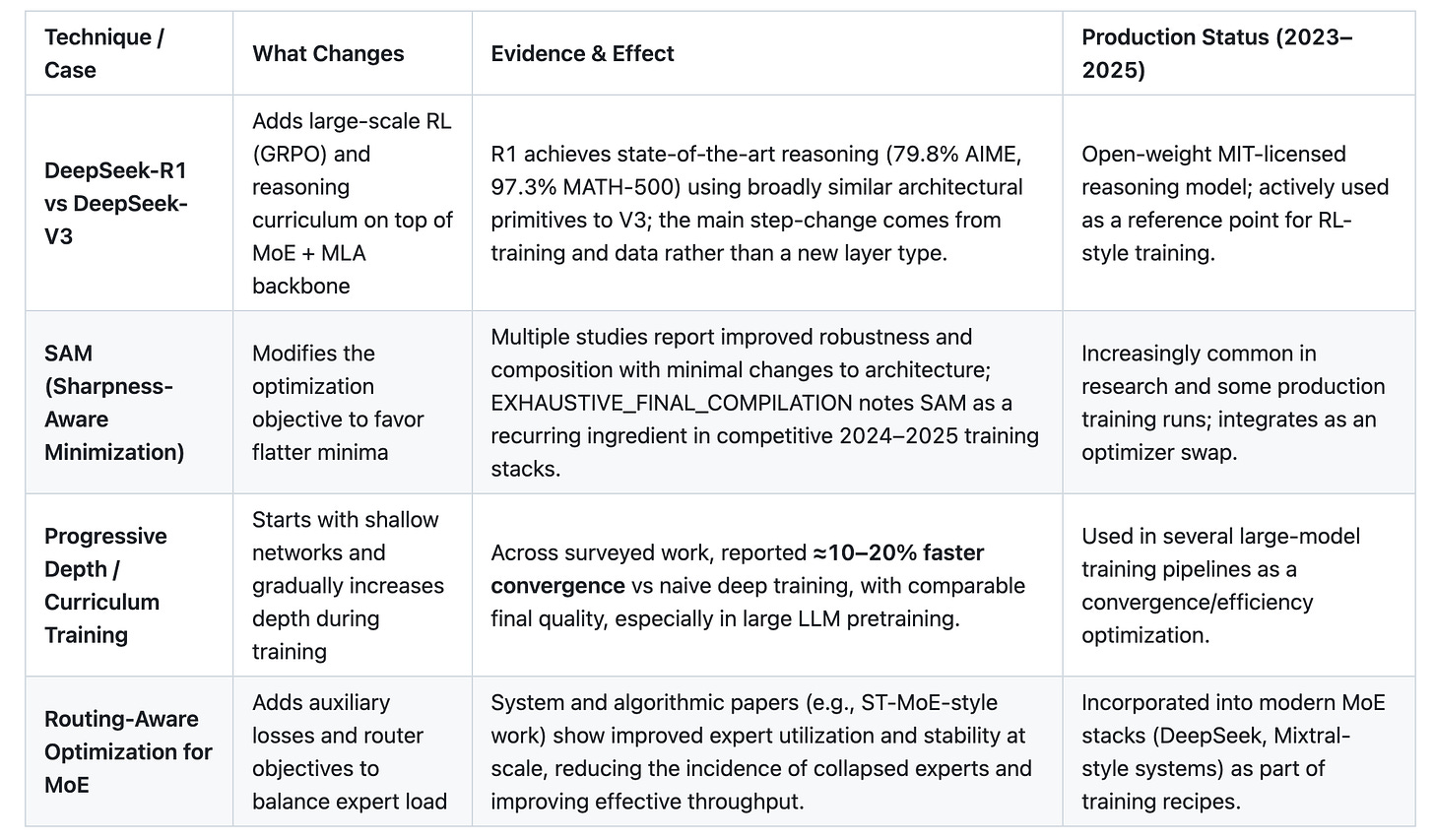
Insight: The most dramatic recent gains in reasoning and efficiency often come from training recipes and optimization choices layered on top of relatively stable architectural primitives (MoE, efficient attention), reinforcing the view that, on today’s hardware, training innovation is where much of the near-term leverage lies.
Glossary and Key Concepts
This glossary collects the main acronyms and concepts used across the three Acts and the Appendix, with short but detailed explanations aimed at readers who know modern deep learning but may not live inside LLM infra day-to-day.
Attention and Memory
Attention (Self-Attention)
Mechanism that lets each token in a sequence attend to every other token, computing a weighted sum of their representations. In standard Transformer self-attention, each position produces Query (Q), Key (K), and Value (V) vectors; attention weights are computed as a softmax over Q·Kᵀ and used to mix the V vectors. This gives models flexible, content-based access to the entire context, at the cost of O(n²) memory and compute in the sequence length.
Multi-Head Attention (MHA)
Original Transformer attention variant in which several independent attention “heads” run in parallel, each with its own Q/K/V projections and slightly different focus. Outputs from all heads are concatenated and linearly projected. MHA improves expressiveness but scales memory and compute linearly in the number of heads and quadratically in sequence length.
Grouped-Query Attention (GQA)
An efficient attention variant where many Query heads share a smaller number of Key/Value heads. For example, 8 Query heads might share 1 Key and 1 Value head. This reduces the size of the KV cache (and memory bandwidth) without significantly degrading quality, especially for large models. GQA is a “weight-only” change—no new kernels are required—so it spreads quickly once integrated into a model family.
Multi-Query Attention (MQA)
An earlier efficiency variant in which all Query heads share a single Key and Value head. This maximizes KV sharing but can be less flexible than GQA. Some early Gemini versions used MQA, with later models and other families converging more on GQA-like patterns that balance efficiency and expressiveness.
Multi-Head Latent Attention (MLA)
An attention mechanism introduced by DeepSeek in which the KV cache is projected into a low-rank latent space before being stored. Instead of keeping full-resolution K/V vectors for every token, MLA maintains a compressed latent representation and attends over that; this significantly reduces memory footprint and bandwidth. MLA still uses dense matrix multiplications and fits well on GPUs, but changes the storage and retrieval pattern to support long contexts (e.g., 128K) and large MoE models.
KV Cache (Key-Value Cache)
During autoregressive generation, models cache the Key and Value tensors from previous tokens so they don’t have to recompute them at each step. For long contexts and large models, this cache dominates memory usage—often hundreds of GB at 128K context for 70B+ models if stored naïvely. Techniques like GQA, MLA, and FlashAttention-style kernels largely exist to make the KV cache more manageable.
FlashAttention
An IO-aware attention algorithm that reorders computation to respect GPU memory hierarchies. Instead of materializing the full n×n attention matrix in HBM (off-chip memory), FlashAttention tiles the computation into blocks that fit in SRAM (on-chip cache), computes attention over those blocks, and discards them without ever writing the full matrix to HBM. The result is 2–4× speedups and 10–20× memory savings at long sequences, turning attention from a memory-bound to a compute-bound operation and enabling much longer contexts.
Sliding-Window Attention (SWA)
An attention pattern where each token attends only to a local window of nearby tokens, rather than the entire sequence. This reduces the effective complexity from O(n²) to roughly O(n·w), where w is the window size, and is useful for long contexts where many long-range interactions are unnecessary. Mistral 7B is a canonical example of GQA + SWA in production.
Sparse Attention / DeepSeek Sparse Attention (DSA)
Sparse attention restricts which positions can attend to which others, either via fixed patterns (e.g., blocks, dilations) or learned structures, to reduce computation and memory. DeepSeek’s DSA is a specific form of sparse attention that reduces complexity from O(L²) to O(L·k) by attending only to selected key positions, enabling long contexts (e.g., 128K) in V3.2 with more predictable memory use.
RoPE (Rotary Position Embeddings)
A positional encoding method that rotates query/key vectors in a way that encodes relative positions while preserving certain algebraic properties of the dot product. RoPE supports extrapolation to longer contexts and has become a de facto standard in modern LLMs (Llama, Mistral, Qwen, etc.).
Mixture-of-Experts and Conditional Execution
Mixture-of-Experts (MoE)
An architectural pattern in which certain layers (usually the feed-forward / MLP blocks) contain multiple “experts,” and a small router network selects a subset of experts (e.g., top-1 or top-2) for each token. This makes the layer’s parameters “sparse”: the total parameter count can be very large, but only a small fraction is active per token. MoE is a form of conditional execution—different tokens route to different compute paths—enabling large capacity at lower per-token compute cost, at the price of more complex training and serving.
Experts and Router
In MoE, each expert is usually a feed-forward network (FFN) or similar module. A router (often a small linear layer per token) produces a distribution over experts, and a sparse selection (top-k or expert-choice) determines which experts process each token. Good routing is crucial for performance and load-balancing; poor routing leads to “collapsed experts” and low utilization.
Conditional Execution
An umbrella term for mechanisms that allow the model to dynamically select which computations or parameters to use, conditioned on the input or context. This includes:
- Hard routing (MoE): token → expert selection.
- Soft routing (attention): token → weighted combination of other tokens.
- Structured sparsity (sparse attention, SWA): token → subset of positions computed.
- Task-conditional parameters (LoRA/adapters): task → which low-rank parameter additions are active. Conditional execution is central to scaling capacity without uniformly increasing compute for every token.
FasterMoE / Aurora / MoE System Stacks
System-level implementations and optimizations for serving MoE models efficiently. These frameworks design block-sparse kernels, expert sharding strategies, and communication patterns to keep GPUs well utilized. They are a key part of why MoE became practical in production: without efficient system support, MoE can be 3–15× slower than dense models despite fewer active parameters.
State Space Models (SSMs) and Mamba
State Space Models (SSMs)
Models that represent sequences via latent “state” variables evolving over time according to linear or nonlinear state-space equations. Instead of attending over the full sequence, SSMs update a recurrent hidden state as tokens come in, offering nominal O(n) complexity and fixed memory in sequence length. In practice, they can be very efficient for certain long-sequence tasks but have historically struggled with in-context learning and arbitrary long-range interactions compared to attention.
Mamba
A specific SSM variant that introduces “selective state spaces”—mechanisms that allow the model to dynamically control which parts of the state get updated. Mamba and its variants have shown strong efficiency and competitive performance at small-to-medium scales (up to 7B), including Falcon Mamba 7B. However, as of late 2025, no pure Mamba model has been publicly demonstrated at 13B+ or frontier scale; above 7B, SSM-style blocks mainly appear inside hybrids with attention.
Hybrid SSM+Attention Architectures (Jamba, Falcon-H1, Qwen3-Next)
Architectures that mix SSM-like blocks with attention layers to get the best of both worlds: SSMs for efficient local/sequential processing and attention for flexible global dependencies and in-context learning. Examples include:
- Jamba: Alternating Mamba and attention layers.
- Falcon-H1: Parallel mixtures of Mamba2-like and attention components.
- Qwen3-Next: Linear attention (e.g., Gated DeltaNet) + gated attention + MoE.
These hybrids show how SSMs can be powerful components without replacing attention outright.
Optimization, Training, and RL
SAM (Sharpness-Aware Minimization)
An optimization technique that modifies the gradient update to favor flatter regions of the loss landscape. Instead of minimizing the loss at the current parameters, SAM approximately minimizes the worst-case loss within a small neighborhood in parameter space. This tends to produce models that generalize better and are more robust, at modest additional compute cost. In the LLM context, SAM has been used as a drop-in optimizer improvement in some large training runs.
Progressive Depth / Curriculum Training
A training strategy in which models start training with shallower networks (fewer layers) and progressively increase depth as training progresses, or gradually “unfreeze” deeper layers. This can lead to faster convergence—often ≈10–20% wall-clock savings compared to training a full-deep network from scratch—while reaching similar or better final performance. It is a training-level innovation that leverages the same architecture more efficiently.
Routing-Aware Optimization (for MoE)
Training methods that explicitly optimize the MoE router and expert usage: auxiliary losses to balance load, penalties for collapsed experts, and specialized temperature schedules or regularizers. These methods improve expert utilization and stability, which in turn improves effective throughput and quality. ST-MoE-style work and DeepSeek’s MoE stacks are examples of routing-aware optimization in action.
GRPO (Group Relative Policy Optimization)
A reinforcement learning algorithm used in DeepSeek-R1, among others, to train reasoning behavior. GRPO is a variant of policy gradient methods that compares performance across groups of trajectories, focusing updates on relatively better reasoning chains. It allows the model to discover multi-step reasoning strategies by rewarding useful trajectories, even when supervised labels are sparse or noisy.
Retrieval and Memory-Augmented Methods
RAG (Retrieval-Augmented Generation)
A design pattern in which a language model is paired with an external retrieval system (often a vector database or search index). At query time, relevant documents or snippets are retrieved based on the input, and those retrieved chunks are fed into the model’s context. This effectively gives the model access to a much larger “memory” than its fixed context window, without changing its architecture: the GPU still runs the same Transformer-style computations, but over retrieved text instead of a monolithic long prompt.
Infrastructure and Hardware
GPU Primitives / Tensor Cores
Modern GPUs (e.g., NVIDIA A100/H100) are optimized around dense matrix multiplications (GEMMs) and tensor-core operations. A “hardware-compatible” neural primitive is one that can be implemented as regular, batched GEMMs that keep tensor cores busy. Operations that require irregular scatter/gather, small non-vectorized ops, or sequential dependencies tend to underutilize the hardware and are harder to scale.
HBM and SRAM (Memory Hierarchy)
HBM (High Bandwidth Memory) is large but slower off-chip memory on GPUs, while SRAM (on-chip cache/registers) is small but extremely fast. Efficient kernels minimize data movement between HBM and SRAM by reusing data in SRAM as much as possible. Both FlashAttention and MLA are designed explicitly around this hierarchy.
Block-Sparse Operations
Sparse computations where nonzero elements cluster in blocks rather than arbitrary positions, making them amenable to efficient GPU implementations. MoE and many sparse attention variants are implemented as block-sparse matmuls to preserve parallelism and compatibility with GPU primitives.
Other Architectures and Research Directions
KANs (Kolmogorov-Arnold Networks)
Architectures that replace standard linear layers and fixed activations with spline-based, learnable functions on edges, motivated by Kolmogorov-Arnold representation theorems. They offer a more flexible function class in principle but involve spline evaluations that do not map cleanly to dense GEMMs, making them less hardware-friendly. As of 2023–2025, KANs have generated research interest and hype but have not been demonstrated at frontier LLM scale.
Neural ODEs (Neural Ordinary Differential Equations)
Models that interpret layer depth as a continuous variable and use ODE solvers to evolve hidden states. This offers theoretical elegance and continuous-depth flexibility, but ODE solvers are iterative and sequential, conflicting with GPUs’ need for large, regular batches of parallel work. Neural ODEs have influenced theory and some niche applications but have not become a mainstream architecture for large-scale LLMs.
Capsule Networks
Architectures that group neurons into “capsules” and use routing-by-agreement mechanisms to decide how lower-level capsules contribute to higher-level ones. They aim to capture part-whole relationships and invariant representations. However, the routing logic is prescriptive and computationally heavy, and despite early excitement, capsule networks have not been adopted in large-scale production LLMs; they mostly remain a historical example of a compositional idea that did not cross the infra chasm.
Hardware and Kernel Primer
A mental model for how hardware, kernels, and frameworks shape what “actually works.”
This primer gives a quick, practical view of how GPU hardware, kernels, and frameworks fit together, and why they create the Hardware Compatibility Filter and Infrastructure Lag Pattern described in the main article. For definitions of specific acronyms and components (HBM, SRAM, GEMM, tensor cores, etc.), see the Glossary and Key Concepts section.
1. The Three-Layer Stack
At a high level, modern LLM infrastructure looks like a three-layer stack:
- Hardware – GPUs, tensor cores, HBM/SRAM, interconnects (PCIe, NVLink).
- Kernels and Libraries – CUDA/Triton kernels, cuBLAS/cuDNN, FlashAttention, block-sparse matmuls.
- Frameworks and Models – PyTorch/JAX operators, Transformer/MoE/SSM blocks, full model architectures.
The key idea: models only run fast if their operations can be expressed as a small number of highly optimized kernels that fit the hardware well. Every time you invent a new primitive that needs a new kernel, you pay an integration and validation tax across this stack.
2. What a Kernel Actually Is
In this context, a kernel is not just an algorithm on paper; it is the concrete, low-level implementation of that algorithm on GPUs:
- It specifies how work is divided over threads, warps, and thread blocks.
- It defines how data is laid out in memory (HBM vs on-chip SRAM/shared memory vs registers).
- It chooses tiling strategies (how matrices are sliced) to keep tensor cores fed and minimize memory traffic.
- It must be numerically stable, performant across different GPU generations, and integrated into libraries (e.g., PyTorch, JAX).
Writing a good kernel is hard. Making it production-grade is harder: you need tests, fallbacks, debugging hooks, and framework integration. This is why “kernel-level changes” show a ~24-month lag from paper → library → framework → production (see Appendix, Table 4).
3. How Hardware Shapes Compatibility
Modern GPUs (A100, H100, etc.) are built around three key properties:
- Dense matrix multiplications (GEMMs) on tensor cores.
- Hierarchical memory – small, fast SRAM on-chip + large, slower HBM off-chip.
- Massive parallelism – thousands of threads executing similar instructions in lockstep.
A technique is hardware-compatible if:
- It can be expressed as regular, batched GEMMs or other well-optimized primitives.
- It keeps parallel threads doing similar work with minimal branching.
- It minimizes expensive HBM↔︎SRAM transfers by reusing data in on-chip memory.
Techniques that require irregular scatter/gather, heavy branching, or inherently sequential computation (e.g., iterative solvers) tend to underutilize the hardware and are much harder to push to frontier scale.
4. Concrete Examples
4.1 FlashAttention: Same Math, Better Kernel
-
Problem: Standard attention materializes an n×n attention matrix in HBM and repeatedly reads/writes large Q/K/V tensors, making it memory-bound and limiting context length.
-
Kernel innovation: FlashAttention reorganizes the computation into tiles that fit into SRAM. It loads small blocks of Q/K/V, computes attention for those blocks, and discards intermediate results without writing the full matrix to HBM.
-
Hardware match:
- Uses dense GEMMs on tensor cores.
- Minimizes HBM traffic; reuses data in SRAM.
- Preserves exact attention math (no approximation).
This is why FlashAttention could become a near-universal drop-in: it is a kernel-level improvement that respects GPU primitives while keeping the higher-level abstraction identical. The price was ~24 months of integration work across libraries and frameworks (Appendix, Table 4).
4.2 GQA and MLA: Weight-Only vs Compressed KV
-
GQA (Grouped-Query Attention):
- Changes the weight shapes so many Query heads share fewer Key/Value heads.
- Uses the same underlying GEMM kernels as standard MHA.
- Effect: smaller KV cache, less memory traffic; no new kernels required.
- Integration cost: Weight-only change → adoption driven by retraining cycles (~12 months; Appendix, Table 4).
-
MLA (Multi-Head Latent Attention):
- Projects KV vectors into a low-rank latent space before caching.
- Still uses dense GEMMs, but changes how KV is stored and retrieved.
- Effect: much smaller KV cache and bandwidth at long contexts (DeepSeek V2/V3).
- Integration cost: Mostly handled via existing linear-algebra kernels; complexity lives in model code and training, not low-level kernels.
In both cases, the operations remain “tensor-core friendly,” which is why they spread quickly once shown to work.
4.3 MoE: Conditional Compute Needs Kernel + System Help
Mixture-of-Experts introduces block-sparse compute and conditional routing:
-
Multiple experts (FFNs) per layer, with a router choosing a subset per token.
-
On paper, this saves compute: only a fraction of the experts are active per token.
-
On hardware, naïve implementations can be 3–15× slower than dense models because:
- Tokens for a given expert may be scattered across batches.
- Expert weights must be moved in and out of SRAM frequently.
- Communication overhead across GPUs can dominate.
Efficient MoE requires:
- Block-sparse kernels that can pack token assignments into regular blocks and run them as GEMMs.
- Expert sharding and load balancing across GPUs (e.g., MegaBlocks, FasterMoE, Aurora).
- Serving stacks that know how to route tokens to experts, keep experts resident in memory, and handle dynamic loads.
This is why MoE falls into the Level 3 (serving + distributed system) category and shows a ~36-month lag from Switch → Mixtral/DeepSeek/Llama 4 (Appendix, Table 4).
4.4 SSMs vs Attention: Parallelism Gap
State Space Models (SSMs) like Mamba use sequential state updates:
- Each token updates a latent state based on the previous state and current input.
- Even with clever “parallel scan” algorithms, the structure is less naturally parallel than attention’s big batched matmuls.
On GPUs:
- Attention can compute many Q·Kᵀ matmuls in parallel across tokens, heads, and layers.
- SSMs must simulate a recurrence, which is more sequential and often requires custom kernels that are harder to optimize.
The result in 2023–2025:
- Pure Mamba/SSM models are very efficient up to 7B (Falcon Mamba 7B).
- Beyond that, all successful large deployments use SSMs as components in hybrids with attention, not as full replacements (Appendix, Table 3).
This illustrates how parallelism and kernel complexity can limit which architectures make it to frontier scale on today’s GPU stacks.
5. How This Creates Infrastructure Lag
Putting it together, the Infrastructure Lag Pattern emerges naturally from these layers:
-
Weight-only changes (e.g., GQA):
- Only model definition and training code change.
- No new kernels or serving infra.
- Adoption timeline: ≈12 months (one or two retraining cycles).
-
Kernel-level changes (e.g., FlashAttention):
- Require new CUDA/Triton kernels, library support, and framework integration.
- Need extensive testing and validation across models and hardware.
- Adoption timeline: ≈24 months from paper to “standard practice.”
-
Serving + distributed-system changes (e.g., MoE):
- Need kernels, framework ops, and new serving stacks (expert sharding, routing, load balancing).
- Often require rewriting major parts of infra and monitoring.
- Adoption timeline: ≈36 months from initial paper to widespread production use.
Architectural ideas that align with existing kernels and hardware (GQA, RoPE, RMSNorm) diffuse quickly. Those that require entirely new kernels or system designs (Flash, MoE, SSMs at scale) move more slowly. Those that fight GPU primitives (e.g., heavy spline evaluations in KANs, iterative solvers in Neural ODEs) face the steepest uphill battle and, so far, have not crossed into frontier-scale production.
This is the practical substrate of the Hardware Compatibility Filter: it is not just about mathematical elegance, but about how gracefully a technique flows through hardware, kernels, frameworks, and serving systems.
Bibliography and References
This bibliography collects the main external sources cited in the article “What Actually Works: The Hardware Compatibility Filter in Neural Architecture (2023–2025)”.
Primary sources (papers, technical reports, official model cards/docs) back quantitative and architectural claims. Secondary sources (e.g., Wikipedia, third-party analyses) are used only for high-level summaries and inferred details of closed models and are explicitly labeled as such.
1. Mixture-of-Experts and Conditional Computation
- Fedus, W. et al. (2021). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv:2101.03961. Original large-scale sparse MoE for language models, establishing Switch as a practical scaling path.
- Lepikhin, D. et al. (2020). GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. arXiv:2006.16668. Introduces GShard and conditional computation techniques for scaling models across many devices.
- Du, N. et al. (2021). GLaM: Efficient Scaling of Language Models with Mixture-of-Experts. arXiv:2112.06905. Demonstrates Google’s GLaM MoE architecture and its efficiency–quality trade-offs.
- Zhou, Y. et al. (2022). Mixture-of-Experts with Expert Choice Routing. NeurIPS 2022. arXiv:2202.09368. Proposes expert-choice routing to improve MoE load balancing and training stability.
- Shazeer, N. et al. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. arXiv:1701.06538. Early MoE paper showing sparsely-gated experts can scale to very large parameter counts.
- Puigcerver, J. et al. (2023). Soft Mixture of Experts. arXiv:2308.00951. Representative “Soft MoE” work from Google scaling MoE with weighted expert combinations.
- ST-MoE (Google Research, 2022). Large-scale sparse MoE (~269B parameters) with stabilized routing (e.g., z-loss) used as a modern reference point for training and inference cost vs dense baselines.
- Mixture of Experts in the Era of Large Language Models (2024). Survey of MoE architectures and deployment patterns in LLMs, covering Mixtral-8×7B, Grok-1, DBRX, Arctic, DeepSeek-V2/V3 and related systems.
- FasterMoE context-length study (2023–2024). System benchmarking paper analyzing MoE throughput vs sequence length and batch size; used to derive context-length degradation curves in the MoE dataset.
- Towards MoE Deployment: Mitigating Inefficiencies in Mixture-of-Experts Inference. arXiv:2303.06182. Analyzes practical deployment inefficiencies of MoE and proposes mitigation strategies.
- Optimizing MoE Inference Time (Aurora system, 2024). arXiv preprint focused on MoE inference optimization, providing ≈2.4–3.5× speedup numbers over dense baselines.
- Mistral AI (2023–2024). Mixtral 8×7B technical report and Hugging Face model cards for
Mixtral-8x7BandMixtral-8x7B-Instruct. Documents the Mixtral sparse MoE architecture and its benchmark results. - DeepSeek-AI (2024). DeepSeek-V3 Technical Report. arXiv:2412.19437 and associated Hugging Face model cards (e.g.,
deepseek-ai/DeepSeek-V3,deepseek-ai/DeepSeek-V3.2-Exp). Describes DeepSeek’s MoE + MLA architecture and long-context performance. - Riquelme, C. et al. (2021–2022). Scaling Vision with Sparse Mixture of Experts (Vision MoE / V-MoE). Extends MoE ideas to vision models, demonstrating benefits beyond NLP.
- NVIDIA GB200 NVL72 and related vendor documentation describing hardware optimized for large-context MoE workloads. Vendor materials illustrating hardware co-designed for large MoE and long-context serving.
2. Flash Attention and Infrastructure Lag
- Dao, T. et al. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. arXiv:2205.14135. Introduces the original IO-aware tiling algorithm that makes exact attention memory-efficient and fast on GPUs.
- Dao, T. et al. (2023). FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. arXiv:2307.08691. Improves FlashAttention with better parallelism and work partitioning, increasing utilization.
- PyTorch 2.0 / 2.2 release notes and documentation for
scaled_dot_product_attentionand the FlashAttention2 backend (Jan 2024). Framework integration evidence for FlashAttention-style kernels becoming standard. - IBM Granite 13B model card (first openly confirmed major model using FlashAttention). Early production confirmation of FlashAttention usage in a large open-weight model.
- Microsoft Phi-3 documentation (2024) referencing FlashAttention usage. Confirms FlashAttention in Microsoft’s Phi-3 models.
- Google Gemma 2 model card (2024) referencing FlashAttention2. Confirms FlashAttention2 adoption in Google’s Gemma 2 family.
- FlashAttention-3 Hopper (H100) technical reports and documentation (2024). Describes Hopper-optimized FA3 kernels and their performance characteristics.
- FlashInfer serving library documentation (2025) reporting ≈29–69% latency reductions in inference. Serving-level library built on FlashAttention kernels, showing end-to-end latency gains.
- Efficient Large Language Models (TMLR 2024). Survey of efficient attention mechanisms and LLM optimizations, covering hardware-efficient attention (FlashAttention family), compact attention (KV compression), sparse and linear attention methods.
3. State Space Models and Hybrid Architectures
- Gu, A. et al. (2021). Efficiently Modeling Long Sequences with Structured State Spaces (S4). arXiv:2111.00396. Introduces structured state-space models as efficient sequence models for long contexts.
- Gu, A. and Dao, T. et al. (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv:2312.00752. Presents Mamba, a selective SSM with linear-time sequence modeling capabilities.
- From S4 to Mamba: A Comprehensive Survey (2025). arXiv:2503.18970. Survey of structured state-space models, tracing the evolution from S4 to Mamba and summarizing empirical findings on scalability and limitations.
- A Survey of Mamba (2025). arXiv:2408.01129 (June 2025 update). Consolidates empirical results and design variants of Mamba-style models, emphasizing their strengths up to ≈7B parameters and challenges at larger scales.
- Falcon Mamba 7B model card and technical brief describing a 7B pure Mamba model trained on 5.5T tokens and benchmarks vs Llama 3.1 8B, Mistral 7B, Gemma 7B. Documents the strongest pure Mamba model and its comparative performance.
- AI21 Labs (2024). Jamba hybrid Mamba+Attention model (official blog and Hugging Face cards). Describes a production hybrid architecture that alternates Mamba and attention layers.
- TII (2024). Falcon-H1 hybrid model combining attention and Mamba2-style blocks. Presents a parallel hybrid SSM+attention design over a range of scales.
- Qwen3-Next technical reports and model cards describing linear attention (e.g., Gated DeltaNet) plus gated attention and MoE for capacity. Detail a frontier hybrid architecture combining linear attention, gated attention, and MoE for long context and capacity.
- NVIDIA Nemotron technical reports describing hybrid architectures incorporating Mamba-style SSM blocks for efficiency. Provide examples of efficiency-focused hybrids using SSM-like blocks.
- Falcon 2 (TII) documentation for hybrid architectures that incorporate SSM-style blocks. Confirms SSM-style components inside modern Falcon architectures.
4. Training and Optimization Techniques
- Foret, P. et al. (2020). Sharpness-Aware Minimization for Efficiently Improving Generalization. arXiv:2010.01412. Introduces SAM, an optimizer modification favoring flat minima for better generalization.
- Progressive depth / curriculum training work demonstrating faster convergence via increasing depth over training (representative 2020–2023 literature). Represents modern progressive training schemes that improve convergence speed.
- Routing-aware optimization and load-balancing methods for MoE models (e.g., z-loss and auxiliary losses in ST-MoE-style work). Captures router-focused training techniques that stabilize and balance MoE experts.
- Liu, K. et al. (2025). Reinforcement Learning Meets Large Language Models: A Survey of Advancements and Applications Across the LLM Lifecycle. arXiv:2509.16679. Survey of RL methods applied across pre-training, alignment fine-tuning, and reinforced reasoning for LLMs, with a focus on RLVR, datasets, benchmarks, and tooling.
- Sun, H. and van der Schaar, M. (2025). Inverse Reinforcement Learning Meets Large Language Model Post-Training: Basics, Advances, and Opportunities. arXiv:2507.13158. Survey framing LLM alignment through inverse RL, emphasizing reward modeling from human data, evaluation metrics, and open challenges.
5. Frontier Model Documentation and Model Cards
- Meta AI. Llama 2 (7B/13B/70B) model card and technical report (2023). Documents the dense Llama 2 family and its core architectural choices.
- Meta AI. Llama 3 and Llama 3.1 model cards (e.g.,
Meta-Llama-3-8B,Meta-Llama-3-70B,Meta-Llama-3.1-405B) confirming GQA, RoPE, RMSNorm, and FlashAttention usage. Provide official confirmation of efficient attention and normalization patterns in Llama 3. - Meta AI. Llama 4 (Scout / Maverick) launch materials (2025) describing the MoE pivot from dense Llama 3. Establish Meta’s first public MoE architecture and its expert configuration.
- OpenAI. GPT-4 system card and associated blog posts (2023). High-level description of GPT-4’s capabilities, training data, and safety considerations.
- OpenAI. GPT-4 Turbo launch materials (2023). Documentation describing cost, latency, and context improvements for GPT-4 Turbo.
- OpenAI. GPT-4o release blog and system card (May 2024). Introduces GPT-4o as a natively multimodal model with improved latency and cost.
- OpenAI. GPT-5 system card and launch posts (Aug 2025). Official materials describing GPT-5’s capabilities and deployment properties.
- SemiAnalysis and similar third-party technical analyses (secondary / inference sources) used for inferred architectural details of closed models. Independent analyses used to hypothesize MoE/architecture internals for closed models.
- Google DeepMind. Gemini technical reports and the “Gemini (language model)” Wikipedia entry (secondary summary) describing MQA/GQA and multimodal transformer architecture. Official and secondary sources summarizing Gemini’s architecture and attention variants.
- Mistral AI. Mistral 7B paper (arXiv:2310.06825). Technical report on the Mistral 7B dense transformer and its performance.
- Mistral AI. Mixtral 8×7B technical report and model cards confirming sparse MoE architecture (8 experts, 2 active per token). Describes the Mixtral MoE architecture and benchmark results.
- DeepSeek-AI. DeepSeek-V2 technical report and GitHub configs. Documents DeepSeek V2’s architecture and training setup.
- DeepSeek-AI. DeepSeek-V3 technical report (arXiv:2412.19437). Presents DeepSeek V3’s MoE + MLA architecture and performance.
- DeepSeek-AI. DeepSeek-R1 launch blog and model documentation (Jan 2025). Provides details on DeepSeek R1’s reasoning training and performance metrics.
- Anthropic. Claude model cards and system cards for Claude 2, Claude 3, and Claude 4.x. Summarize Claude family capabilities, context windows, and safety considerations.
- xAI. Grok-1 release repository (
xai-org/grok-1) and x.ai blog posts for Grok 4.x (e.g., “Grok 4.1”). Provide open weights and architectural notes for Grok models. - Gemma 2 model cards (Google, 2B/9B/27B) confirming GQA and key architectural details. Document Gemma 2’s architecture, GQA usage, and training setup.
- Llama 3.2 / 3.3 model cards confirming GQA and long context windows (e.g., 128K). Confirm GQA and extended context support in later Llama 3 releases.
- Qwen2.5 72B model card documenting GQA configuration, context length, and training setup. Official Qwen 2.5 documentation for attention configuration and context length.
- Falcon 2 11B documentation describing GQA usage and training corpus. Describes Falcon 2’s architecture and training data, including GQA.
- Wikipedia entries: “Llama (language model)”, “Claude (language model)”, “Gemini (language model)” (secondary summaries, as of late 2025) for consolidated public overviews of architecture families. Secondary sources summarizing architecture families for quick reference.
6. Production Deployment, RAG, and Serving Systems
- Product and developer documentation from OpenAI (ChatGPT, GPTs), Anthropic (Claude), and Google (Gemini) describing retrieval-augmented workflows and tool/RAG patterns. Provide concrete examples of how major providers productize RAG and tool integration.
- DeepSpeed, Megatron-LM, FasterTransformer, AITemplate, Unsloth, and related open-source frameworks documenting FlashAttention and MoE support in production-grade stacks. Framework and serving documentation showing kernel and MoE support in real systems.
- Command R / Command R+ (Cohere) product documentation highlighting long-context (128K+) capabilities and RAG-centric workflows. Vendor docs demonstrating long-context and retrieval-centric deployments.
- Llama 3.2 documentation describing extended context windows around 128K tokens. Confirms extended context support and associated techniques in Llama 3.2.
- xAI Grok 1.5 and related documentation noting long-context capabilities. Documentation describing Grok 1.5’s long-context features and usage.
- Qwen 3 and Qwen3-Next technical reports and model cards documenting 128K–256K context windows with sparse attention and memory strategies. Official sources describing Qwen’s long-context and sparse-attention strategies.
- Beyond the Limits: Context Length Extension (May 2024). Survey of long-context techniques, including memory-retrieval augmentation, modified positional encodings, SSM approaches, and sparse attention patterns.
7. Modular and Compositional Learning
- 2025 “Modular Machine Learning” framework papers on modular representations, modular models, and modular reasoning, used to validate the “compositional language” thesis. Introduce a formal framework for modular models and reasoning that aligns with the compositional architecture view.
- Petros, P. (2024). Neural Architecture Design as a Compositional Language (previous post that the current work extends). Earlier article establishing the compositional architecture framing this work builds on.
- Modularity in Deep Learning: A Survey (2023). Survey of modularity across data, task, and model axes, and its impact on compositional generalization and training.
8. Additional 2025 Research Directions (Speculative / Emerging)
These references inform forward-looking observations and are not treated as production-standard techniques.
- 2025 “Neural Attention” paper replacing dot products in attention with small feed-forward networks to capture richer nonlinear interactions in research settings.
- Nested Learning (Google Research, NeurIPS 2025), introducing a multi-level learning paradigm with attention as associative memory for continual learning.
- Hybrid transformer with quantum self-attention applied to molecular generation (SMILES) demonstrating experimental quantum-enhanced NLP architectures (2025).
- Transformer-based neural architecture search (2025) using auxiliary perplexity-based metrics to explore alternative attention computation strategies.
Thanks for reading Petros Rooted Layers! Subscribe for free to receive new posts and support my work.